模块化分析平台·一#
---
创建日期: 2023-04-05
---
关于制作数据分析工具的一些想法。
同事告诉我说数字化部门和事业部的相关人员要做 MicroService, 我听到这种信息,就内自叹气。以防我理解错误,又去搜索了一番。 我的结论是:这和我们有什么关系?我们的业务量完全也没到这层境界。
其实我大概明白他们要干什么。 只是借用这种“热词”,做着完全不一样的事情,徒增我的困惑。
面临的问题#
我们目前存在的一些特点/问题:
采样率高,数据量大,非统计性分析
有几个不同地区,相互之间访问数据受网络限制
非标准化分析,需要自己定义分析工具
工具部署并不容易,没有统一的交互方式,有学习成本
处理过程没有记录,工具只负责处理
下游“客户”需要查看结果的时候,没有合适的工具,也不知道数据、结果存放在哪里,只能看静态报告
另外其实不同部门之间或许有相似的境遇,做着相似的工作,该如何整合这些资源
这些问题由来已久,似乎一直都没有真正被解决。
我一直在搜索有没有一种“分析平台框架”,能够让我快速:
自定义数据结构
自定义分析方法
节点交互与可视化
存储与复现分析过程
在不同条件下批量处理(根据需求可交互)
结果的信息交换(可作为模型被下游分析)
额外加上分析状态管理、项目信息交换
正如另一篇文章中提到的,其实本质都是数据的流动与处理方法。 只是不断试图提升交互性、降低使用门槛,让更多人能便捷使用,以及产生结构化的数据。
分析工具的创建#
我写了几个数据处理的程序,ldm、pch、atc、rdv、pdm等。 都不是什么高级的东西,交互多于算法本身,慢慢热情降低,也不再想做新功能,修修补补。
一路过来看到大家(包括我自己)对于分析工具曾经的构想,一个个败下阵来, 以及后来人的(也包括我自己)另起炉灶,重复着同样的故事。
朴素方法#
最朴素的,像是Jan写的振动处理工具,把不同的功能写在不同的脚本中,各自算是独立的程序。 数据进入一个工具,处理后转换成另一种数据,保存到文件中,再有下一个程序读取。
这已经能够进行数据处理了,只是有许多代码在不同工具间复制。 批量处理不方便,用户也需要来回的切换。 当需要交叉分析的时候,可能得再写一个脚本。
所以我早期想把上下游的各种分析方法整合在一个工具里,做分析不再需要来回切换。 当然目标中也包含批处理,预留接口方便扩展新的分析方法,以及存储为项目可进行回顾、审核。 这个是svt,不过由于“政治不正确”不太方便开展这项工作。
工具管理#
后来写的几个处理程序,其实每个风格都不一样:树状的ldm、固定列式的atc、层叠的pch 和 点线网状的rdv。 有不同的分析需求,但也有重叠的需求:比如简单的数据查看。 这些程序如果能够串起来就好了。
额外可达成将 不同的分析结果纵向放在一起、不同的项目横向放在一起 对比,那可太棒了。
(当时还特别在意数据处理十分杂乱的问题,想要一个框架把这些东西都固定下来,结构化起来。) (说来奇怪,一两年前非常想要改变那种混乱的状态,一想到就非常难受。不知不觉似乎已经坦然接受了,自己还不断写新的专用的脚本。)
所以问题就是要如何把信息、数据流从一个程序导到另一个程序。 每个程序需要定义沟通模型(或者协议),再有一个管理程序去调用他们。 这个是pdm。
每个分析工具可以按照自己的实际需求去实现,功能集成起来内部的交互也更便捷。 它们需要实现框架的协议,接收输入,处理完成后提供输出。 每个程序会有很多内部“模型”,也需要定义一些外部“模型”以便数据交换。 有些情况还可以把已有的第三方工具进行封装,融入到“生态”中。
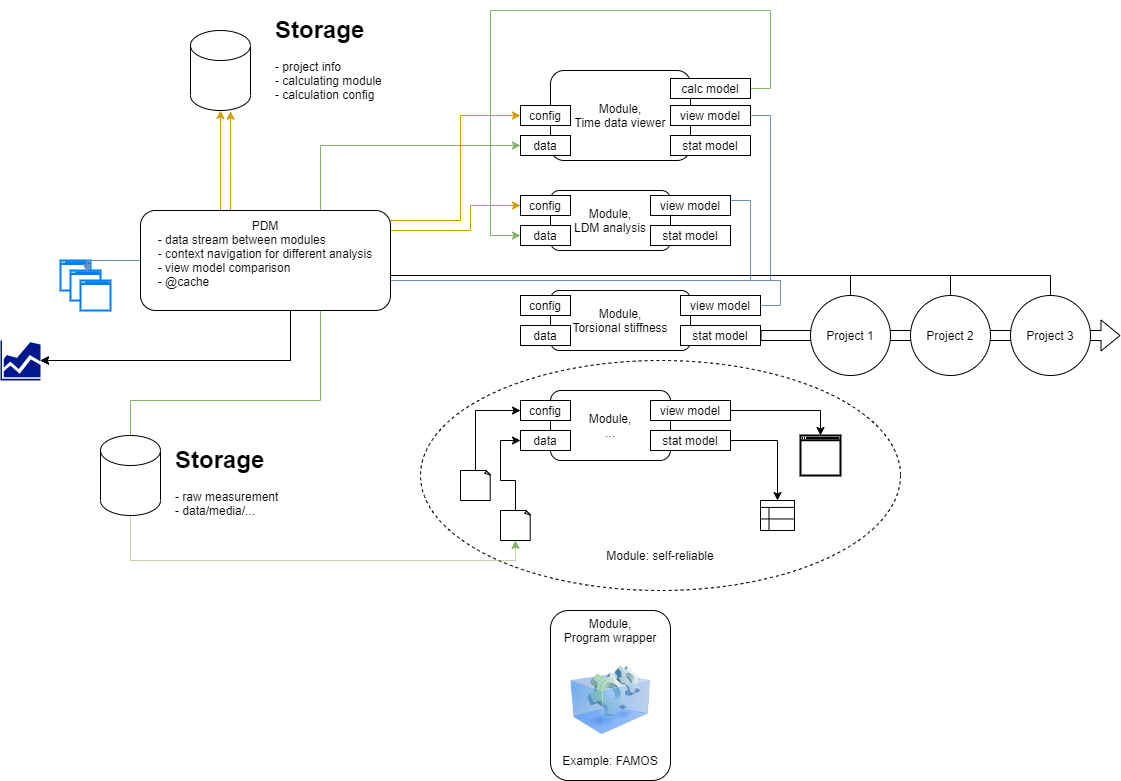
其实一部分就是把“朴素方法”中 文件保存 这个步骤虚化了。 另外有一个统一的入口进行数据分析,不需要关心工具在哪里,在pdm中自动调用。 当然数据处理的结果也保存在pdm-admin所设置的数据库中。 大家都知道在哪里去找工具进行分析,也都知道在哪里找以前的分析结果,因为有统一的入口。
有点像ANSYS的Workbench,我这么觉得。
我想当时非常纠结于存储结构、模型等问题,可能也受MBSE的一些影响。 我们确实已经受够了文档的工作方式,要围绕一点点的信息去写那么多的上下文, 查找不方便,更新不同步,以及结果不能交互,都大大降低了分析结果理解的效率。 不过此乃题外话了。
模块组件#
其实前面提到,有许多的功能在不同的分析工具中是重复的。 比如数据载入,兼容不同的数据源类型;比如简单的数据查看;时域频域转换;基于产品信息的辅助可视化等等。 要么需要把这些功能复制粘贴,要么相当于把一个工具不断扩展用于不同的目的。
不断扩展工具其实没那么容易,每个工具还是有自己独特的目的以及交互需求。 那把共同的部分做成模块化的组件,在不同的工具中调用,也不错。 类似于函数库,不同的是这些是独立的组件库。
比如一个可以兼容各种输入的数据加载组件,一处开发,不同的程序都能得到更新。 不过每个程序也要知道如何用这个组件就是了。

好像能够通用化的组件也比较有限,有时候还要为了组件策略而去适应一些比较特别的数据结构。
比如ChannelRoot的概念在pch中很正常,但是在其它工具中就反而要把这个特性抹平掉。
模块功能#
因为有许多的分析可能性,不同分析的结果可能还需要作为后续分析的输入,树形的方式就不太便利。 这种情况就很容易想到 把不同结点之间用线连接起来 的“图形编程”交互方式。 比如LabVIEW、比如Simulink的那种交互方式。
( 话说为什么不用LabVIEW写工具呢?数采工具也提供了不错的脚本功能。 总还是有些分析需要自己精细控制,提供交互模板,而这些需要通用型的编程语言来完成。 )
数据是节点,也把每个处理方法抽象成节点。 处理方法可以是计算过程,也可以是可视化、交互。
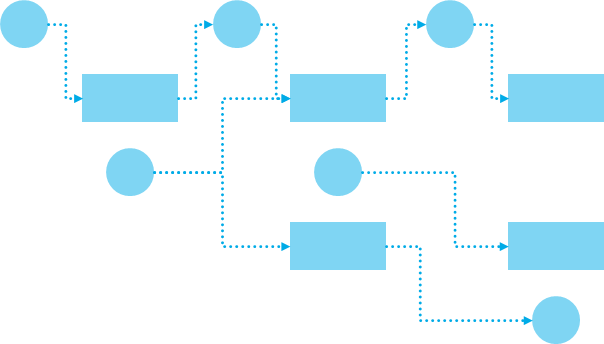
为了批量处理,需要配置独立的运行空间。 出于不同分析的要求,可以根据不同的上下文切换处理方法。
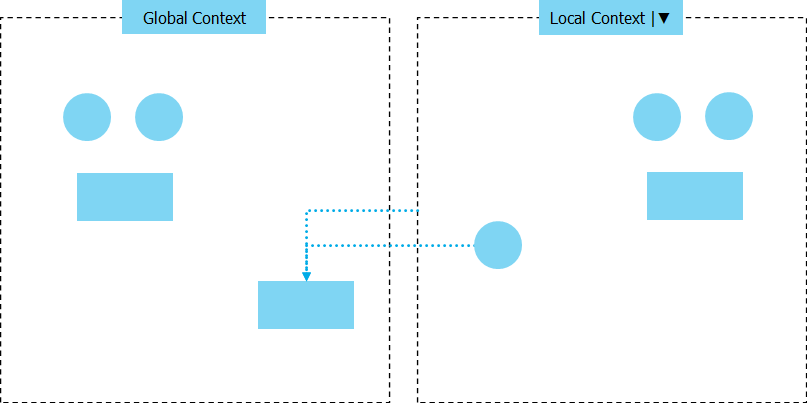
如此可扩展性就非常强了,基本上能够把所有的需求都如此实现。 不过实际上,通用性提升,使用效率就不如专门设计的程序(没有专用的交互,不管什么过程都要编辑再执行)。
这种情况,其实可以看作时一个程序,不断向里加插件。
做了几个工具后发现,即使我再觉得自然的交互,其他人也是不知道如何下手。 所以一个平台的意义,模块功能的意义,也包含减少重复的、独立的实现,让各种功能交互保持一致(虽然让所有功能交互都一致并不是容易的事)。
分析库#
正如前面说的,其实本质还是数据的流动于处理方法。 那么直接定义分析处理的库就好了! 就只需要关心数据结构,以及处理方法本身。
但是其实上有交互的问题,以及库使用说明。 (确实这才是专业用法,不过门槛略高了)
就先不管门槛,那么最适合的方法 (考虑到标准分析、考虑到历史存档/回溯、考虑到远程处理) 就是JupyterNotebook了!
建立一个中心服务,所有分析都有组织地以Notebook形式存放。 好吧,不能不管门槛,确实有点高。
Notebook只比较适合已经组织好的结果,线性运行。 分析过程中如果需要重复调参,或者通过交互获得数据就没那么容易了。 而且还不能显示交互窗口,都会显示在服务器端。
另外,库不成熟、还在修改的时候,现在能够运行的Notebook以后就不一定了。 所以Notebook除了要记录分析过程,还需要能保持运行环境状态,在启动Notebook的时候同时还原。 有点像要求每个Notebook都是一个docker,但实际上不能使用docker运行每一个JupyterNotebook,因为这样会把Notebook隔离开。
(还有一个问题是JupyterNotebook,或者即使是JupyterHub,共享的开启服务的人员权限(网络访问),不能把账号系统和和已有账号关联起来。)